
Python has built-in support for parallel processing via the multiprocessing, subprocess, and thread packages but does not provide any tools to help use system resources effectively to run a set of jobs in parallel. That requires the ability to measure the system resource loads and start queued jobs when sufficient resources become available. It is not hard to build such a package with the right tools and some basic observations.
There are not a lot of python packages for measuring system resources and loads but psutil is a good choice. Using psutil you can obtain metrics such as the total and available system memory, and the total or per-core CPU load. Because psutil cannot measure the i/o load on a system, there is not a good way to avoid running too many i/o-bound jobs in parallel. The best simple approach is probably to add a cap on the number of jobs that can be running in parallel. This is not an ideal approach but can suffice for most purposes until a better package becomes available.
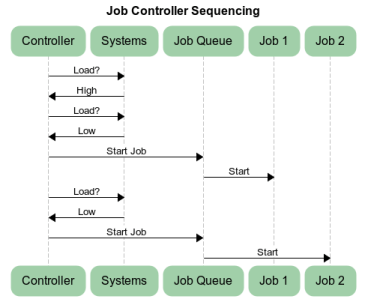
A basic job controller and Job class system can be written with a modest amount of code. This probably has:
- A constructor that may take arguments for the baseline priority level and CPU and RAM thresholds for starting a job. Optional arguments with default job CPU time and RAM resource usage may also be useful.
- Methods for adding and removing jobs to/from the queue.
- A run method that checks the system load and starts one or more jobs if resources allow.
- Optionally, a mechanism for priority escalation/deescalation.
- One or more Job classes that holds the specification for a job, estimates for its resource requirements if available, and a mechanism to run the job when the controller tells it to.
Some considerations in building such a system include:
- Providing an "aggressiveness" priority setting to client code and/or users to let them control the tradeoff between system responsiveness and job throughput will make your job controller more flexible.
- Abstracting the Job concept into classes allows a range of job types to be supported, with customization of the underlying run mechanism (subprocess, multiprocessing, ...), job resource estimates, and so forth.
- A sequential "Job" type is useful when a meta-Job must run a list of smaller jobs in a given order.
- Estimates for a job's resource (CPU and memory) requirements, if available, can be used to refine the logic on starting jobs.
- To limit the number of running jobs (such as to provide a backstop for i/o bound jobs as described above) in a manner that is portable to different parallel packages requires saving and polling the process to count the number running.
- A time.sleep() should normally be used to avoid an excessive load due to polling the system.
- Using the lowest per-core CPU load metric in determining whether to start a job is recommended for most applications but a more sophisticated algorithm that looks at the CPU load distribution could be warranted for a complex or mission-critical system.
- Providing an escalation mechanism may be necessary to get jobs to start on a heavily loaded system. This raises the job starting "aggressiveness" as time passes with no jobs starting and then drops it back to the baseline level after a job starts. Without this your jobs may almost never catch a window when the system is not running at full bore. The escalation logic may need to be tuned to reflect the priority of the jobs compared to other tasks being run.
- Setting the priority escalation strategy and sleep time between system load polling are heuristics that may take some fine tuning to find a good balance.